Why Microarchitecture Matters More Than Algorithms in High-Frequency Trading
Apr 21, 2026 - Tribhuven Bisen
In high-frequency trading, the biggest performance gains come from optimizing how software interacts with hardware (CPU, memory, networking) rather than improving trading models.

Abstract
In high-frequency trading (HFT), the decisive edge often arises not from a new mathematical model but from the way software exploits hardware. When every nanosecond matters, understanding CPU microarchitecture, cache behavior, branch prediction, speculative execution, memory topology (NUMA), and kernel-bypass networking can produce outsized latency gains compared to incremental improvements in trading logic. This whitepaper presents a formal yet accessible treatment for PMs, traders, and engineers: we model latency, explain pipeline hazards with analogies and equations, demonstrate cache-aware data layouts with C++ code, outline kernel-bypass packet paths, and provide system design guidance, benchmarks, and a one-page summary of actionable takeaways.
Contents
- Preface
- Latency as a Formal Budget
- CPU Pipelines, Branch Prediction, and Speculation
- Cache Hierarchy and Data Locality
- NUMA, Thread Placement, and Contention
- Kernel Bypass and NIC-Level Paths
- Microbenchmarking and Profiling
- Performance Comparison Tables
- System Design Blueprint
- Worked Example: Hot-Path Refactor
- Putting It All Together: A Practical Checklist
- Key Takeaways
- Conclusion
1. Preface
This paper was written to clarify a recurring misconception in HFT: that algorithmic ingenuity alone dominates performance. In reality, the performance envelope is defined by physics (propagation delay), CPU microarchitecture (pipelines, caches, predictors), memory topology, and operating system boundaries. The goal is to arm mixed audiences—PMs, traders, and engineers—with a shared, rigorous vocabulary and concrete techniques to reduce tick-to-trade latency.
2. Latency as a Formal Budget
Let end-to-end latency be decomposed as:
where is physical propagation (fiber/microwave), NIC and DMA ingress/egress, OS network stack and scheduling, application processing (parse, decide, risk, build order), and transmit path.
Observation. In colocated HFT, is bounded by geography; and are bounded by hardware. Therefore most controllable variance lies in . Microarchitectural work primarily reduces and avoids via bypass.
2.1. A simple improvement model
If a fraction of is improved by factor (e.g., kernel-bypass improving the stack), then an Amdahl-style bound is:
Microarchitectural work targets a large (broad code paths) and large (order-of-magnitude wins like bypass or cache hits).
3. CPU Pipelines, Branch Prediction, and Speculation
Modern CPUs use deep pipelines and speculative execution to keep functional units busy. A conditional branch that is mispredicted flushes in-flight work.
3.1. Penalty model
If the effective misprediction penalty is cycles, at clock ,
Typical is on the order of 10–20 cycles. Over a hot path with unpredictable branches, the expected stall is .
3.2. Analogy for non-engineers
Think of an assembly line that guesses which part arrives next. A wrong guess forces the line to eject partially assembled items and restart that stage. Reducing surprises (predictable code paths) cuts waste.
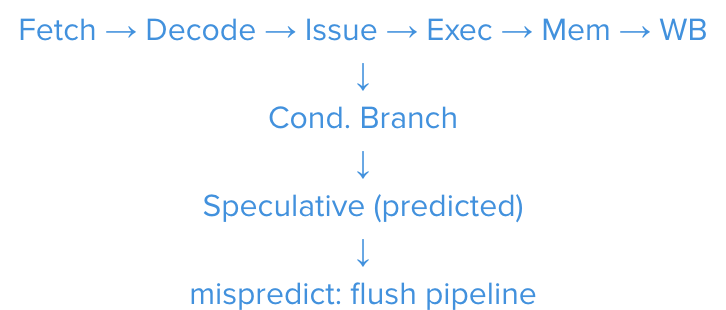
Figure 1: Compact CPU pipeline with speculative branch and misprediction flush.
3.3. Branch-aware coding patterns
Prefer predictable control flow. Replace long if/else chains with table-driven logic or bitwise masks.
/*** Predictable dispatch using lookup tables ***/
using Handler = void(*)(Order&);
extern Handler STATE_DISPATCH[NUM_STATES];
inline void process(Order& o) {
STATE_DISPATCH[o.state](o); // predictable, branchless index
}
Mark likely paths. Compilers accept likelihood hints on hot predicates.
/*** GCC/Clang likelihood hints ***/
#define LIKELY(x) __builtin_expect(!!(x), 1)
#define UNLIKELY(x) __builtin_expect(!!(x), 0)
inline void route(const Quote& q, double th) {
if (LIKELY(q.price > th)) {
fast_buy_path(q);
} else {
slow_sell_path(q);
}
}
Use arithmetic/bit tricks to avoid branches.
/*** Convert boolean to mask and select without a branch ***/
inline void execute_order(bool is_buy, const Quote& q) {
uint64_t m = -static_cast<uint64_t>(is_buy); // 0x..00 or 0x..FF
// select() pattern: (a & m) | (b & ~m)
auto side = (BUY & m) | (SELL & ~m);
place(side, q);
}
4. Cache Hierarchy and Data Locality
4.1. Hierarchical latencies (indicative)
| Level | Access latency | Notes |
|---|---|---|
| L1 data cache | ~0.5–1 ns | per-core, tiny, fastest |
| L2 cache | ~3–5 ns | per-core/cluster |
| L3 (LLC) | ~10–15 ns | shared across cores |
| DRAM | ~100–150 ns | off-core, orders slower |
Implication. A few DRAM misses on a hot path can dominate your entire decision time. Organize data to stream through caches.
4.2. From AoS to SoA
/*** Array-of-Structs (AoS): friendly to objects, unfriendly to caches ***/
struct Order {
double px;
double qty;
char sym[16];
uint64_t ts;
};
std::vector<Order> book; // iterating touches mixed fields -> poor locality
/*** Structure-of-Arrays (SoA): cache + vectorization friendly ***/
struct Book {
std::vector<double> px;
std::vector<double> qty;
std::vector<uint64_t> ts;
// symbols handled separately (IDs or interned)
};
inline double vwap(const Book& b) noexcept {
// contiguous arrays enable SIMD and cache-line efficiency
double num=0.0, den=0.0;
for (size_t i=0;i<b.px.size();++i){
num += b.px[i]*b.qty[i];
den += b.qty[i];
}
return num/den;
}
4.3. Cache-line alignment and padding (diagram)

Figure 2: False sharing vs. aligned counters. Padding/alignment prevents cache-line contention.
4.4. Warm-up & steady state
Pre-touch ("warm") hot data at startup: parse a few messages, exercise parsers and fast paths so instruction/data caches and predictors are primed before opening the gate.
5. NUMA, Thread Placement, and Contention
5.1. NUMA effects
On multi-socket servers, memory is attached to sockets. Remote-node memory adds tens of ns per access. Pin hot threads and allocate memory from the same NUMA node.
/*** Linux: set thread affinity and memory policy (pseudo) ***/
// Use pthread_setaffinity_np() to bind to CPU(s) on NUMA node 0
// Use mbind() or numactl to prefer local memory for hot heaps/buffers
5.2. Lock avoidance
Contention costs explode under parallel load. Prefer:
- Single-producer/single-consumer ring buffers
- Batched atomics; per-thread sharded counters (reduce sharing)
- RCU-style read paths where feasible
/*** SPSC ring (outline) ***/
template<typename T, size_t N>
struct SpscRing {
T buf[N];
std::atomic<size_t> head{0}, tail{0};
bool push(const T& v) {
auto h = head.load(std::memory_order_relaxed);
auto n = (h+1) % N;
if (n == tail.load(std::memory_order_acquire)) return false;
buf[h] = v;
head.store(n, std::memory_order_release);
return true;
}
bool pop(T& out) {
auto t = tail.load(std::memory_order_relaxed);
if (t == head.load(std::memory_order_acquire)) return false;
out = buf[t];
tail.store((t+1)%N, std::memory_order_release);
return true;
}
};
6. Kernel Bypass and NIC-Level Paths
The traditional kernel network stack adds context switches, copies, and scheduling latency. Kernel-bypass frameworks place NIC queues directly in user space (polling loops, zero-copy).
6.1. Polling RX/TX loop (DPDK-style sketch)
/*** RX/TX polling loop (illustrative) ***/
while (likely(running)) {
const int nb = rte_eth_rx_burst(port, qid, rx, BURST);
// parse/route decisions on RX path
for (int i=0;i<nb;++i) process(rx[i]);
// opportunistically transmit accumulated orders
const int sent = rte_eth_tx_burst(port, qid, tx, tx_count);
recycle(tx, sent);
}
6.2. Why bypass wins (conceptually)
- No syscalls in hot path: user-space polls NIC queues
- No scheduler latency: thread spins on core with real-time policy
- Zero/one-copy: NIC DMA to user buffers
Kernel Network Stack Kernel-Bypass (User-space)
┌──────────────┐ ┌──────────────┐
│ NIC (RX) │ │ NIC (RX/TX) │
└──────┬───────┘ └──────┬───────┘
│ │
┌──────▼───────┐ ┌──────▼───────┐
│ IRQ / NAPI │ │HW Queue/DMA │
└──────┬───────┘ └──────┬───────┘
│ │
┌──────▼───────┐ ┌──────▼───────┐
│ TCP/UDP / │ │ User-space │
│ Sockets │ │ Poll Loop │
└──────┬───────┘ └──────┬───────┘
│ │
┌──────▼───────┐ ┌──────▼───────┐
│ App Thread │ │App (Parser/ │
│ │ │ Strategy) │
└──────────────┘ └──────────────┘
Context switches, copies, Zero/one-copy, pinned
scheduler jitter core, predictable
Figure 3: Traditional kernel stack vs. user-space kernel-bypass data path.
7. Microbenchmarking and Profiling (Without Lying to Yourself)
7.1. Common pitfalls
- Dead-code elimination (compiler removes empty loops)
- Constant folding (the "result" known at compile time)
- I/O caching (OS page cache hides disk latency)
- Warm vs. cold cache; noisy neighbors; DVFS/thermal throttling
7.2. Microbenchmark skeleton
/*** Preventing optimization with DoNotOptimize-like barriers ***/
template<typename T>
inline void black_box(T&& v) { asm volatile("" : "+r"(v) : : "memory"); }
void bench_branch(){
volatile uint64_t sum = 0;
const uint64_t N = 100000000; // 1e8 for demo
auto t0 = std::chrono::high_resolution_clock::now();
for(uint64_t i=0;i<N;++i){
bool even = (i & 1u) == 0u;
sum += even ? 1 : 2;
}
black_box(sum);
auto t1 = std::chrono::high_resolution_clock::now();
std::cout << "ns/iter = "
<< std::chrono::duration_cast<std::chrono::nanoseconds>(t1-t0).count()/
double(N)
<< "\n";
}
7.3. Systematic profiling approach
- Measure: CPU sampling, PEBS/LBR, off-CPU time, cache-miss rates
- Isolate: single core, fixed frequency, real-time scheduling
- Stabilize: pin threads, disable turbo/c-states if needed
- Attribute: instruction-level stalls vs. memory vs. branch misses
8. Performance Comparison Tables
All values are illustrative but directionally realistic for hot-path improvements.
8.1. Technique-level summary
| Technique | Typical Gain | Risk | Notes |
|---|---|---|---|
| AoS → SoA | 1.2–1.5× | Low | Improves locality and SIMD opportunities |
| Branch hints / table dispatch | 1.05–1.2× | Low | Works best when distributions are skewed |
| Cache-line alignment / padding | 1.1–1.3× | Low | Avoid false sharing under contention |
| NUMA pinning + local alloc | 1.1–1.3× | Low | Big wins on multi-socket servers |
| Kernel-bypass RX/TX | 2–5× | Med | Requires ops maturity; polling CPU cost |
| Lock-free SPSC rings | 1.2–2× | Med | Great in pipelines; design carefully |
| Warm-up (ICache/DCache/BPU) | 1.05–1.15× | Low | Stabilizes tail-latency and jitter |
8.2. End-to-end illustration
| Configuration | Median Tick-to-Trade | 99p Tick-to-Trade |
|---|---|---|
| Baseline (kernel stack, AoS, locks) | 35 μs | 70 μs |
| Bypass + SoA + pinning + SPSC | 9 μs | 18 μs |
| Bypass + SoA + pinning + SPSC + warm | 7 μs | 12 μs |
9. System Design Blueprint (Conceptual)
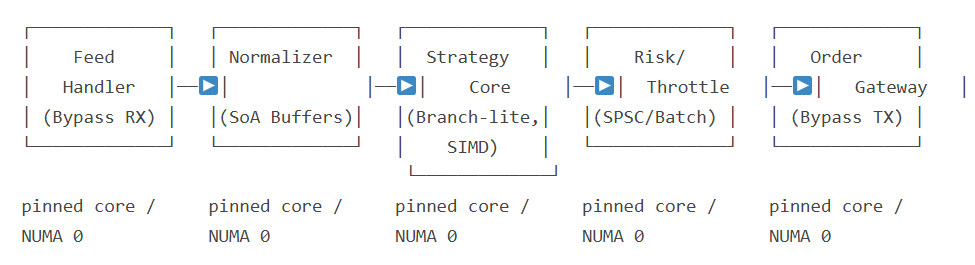
Figure 4: Compact HFT engine pipeline with per-stage SPSC rings and bypass IO.
10. Worked Example: Hot-Path Refactor
10.1. Before (branchy, AoS, kernel stack)
// Pseudocode: branchy parser + decision + syscall TX
void on_packet(const uint8_t* p, size_t n){
Order o = parse_order(p, n); // walks AoS, many cache misses
if(o.type == BUY){
if(o.qty > 0 && o.px > fair + th1) place_buy(o);
else if(o.qty > 0 && o.px > fair) place_passive_buy(o);
else ignore(o);
} else {
// ...similar sell branches...
}
sendto(sock, &o, sizeof(o), 0, ...); // syscall in hot path
}
10.2. After (table-driven, SoA, bypass TX)
// Precomputed handlers; deterministic dispatch
using F = void(*)(const Parsed&, Gateway&);
extern F HANDLERS[MAX_CODE];
inline void on_rx(const uint8_t* p, size_t n){
Parsed z = fast_parse(p, n); // contiguous fields (SoA buffers)
HANDLERS[z.code](z, gw); // table dispatch, branch-lite
gw.flush_burst_if_ready(); // batch TX to NIC queue (bypass)
}
11. Putting It All Together: A Practical Checklist
- Pin hot threads; bind heaps and queues to the same NUMA node.
- Convert hot objects from AoS to SoA; align hot structs to 64B.
- Replace branchy dispatch with tables; add likelihood hints on skewed paths.
- Remove syscalls/locks from hot path; use SPSC rings between stages.
- Adopt kernel-bypass RX/TX; batch and burst to amortize costs.
- Warm caches and predictors at startup; run with stable CPU frequency.
- Profile with HW counters; track stall reasons and branch miss rates.
12. Key Takeaways (1 Page)
For PMs & Traders
- "Faster model" ≠ faster system. Hardware-aware engineering often yields larger, safer, and more durable latency wins than new signals.
- Budget time for microarchitecture and ops: pinning, NUMA, bypass, and cache work require engineering discipline but compound benefits.
- Measure tail latency (p99/p99.9), not just medians. Microarchitectural tuning stabilizes tails, improving realized fill quality.
For Engineers
- Eliminate unpredictable branches; prefer table-driven or mask-based selection.
- Favor SoA, alignment, padding; prefetch judiciously; avoid false sharing.
- Pin threads; allocate memory NUMA-local; isolate noisy neighbors.
- Move RX/TX off the kernel path; batch and burst; use SPSC rings across stages.
- Benchmark honestly (prevent DCE, control frequency); use perf counters to attribute stalls (ICache, DCache, BPU, DRAM).
Rule of Thumb: If a change reduces DRAM misses, removes a syscall, or avoids a mispredicted branch in the hot path, it likely matters more than a new feature in the model.
13. Conclusion
Microarchitecture places hard bounds on what an HFT system can achieve. Aligning software with those bounds—branch predictability, cache locality, memory topology, and kernel bypass—typically delivers multi-× gains where incremental model tweaks cannot. Winning in microseconds demands not just better ideas, but better engineering.